Newsletter

Der genetische Code
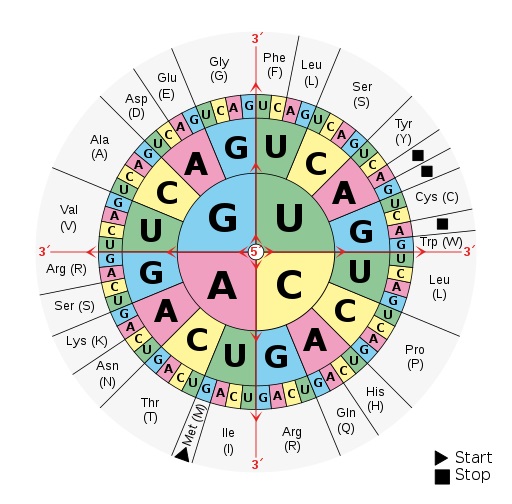
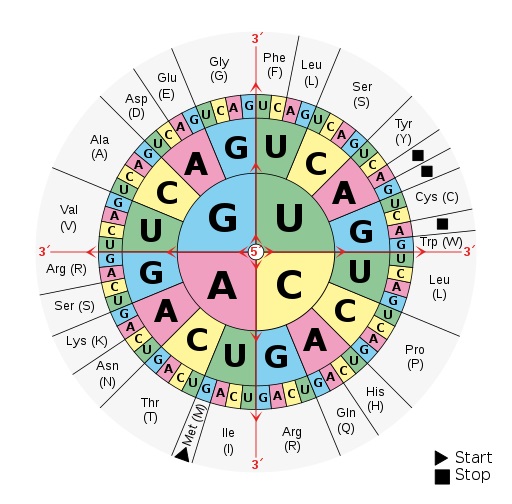
Die Codesonne, Bild: Mouagip, Public domain, via Wikimedia Commons
Die Erbinformation wird von allen Lebewesen als Abfolge der Basen Adenin (A), Guanin (G), Cytosin (C) und Thymin (T) in der Sequenz ihrer Desoxyribonukleinsäure (DNA) gespeichert. Manche Viren verwenden RNA als Informationsspeicher.
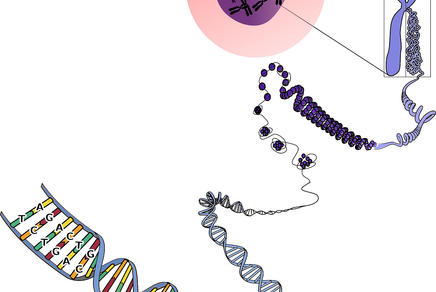
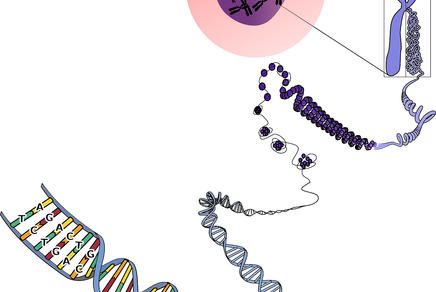
Proteinbiosynthese: Vom Gen zum Protein
Die Gesamtheit der Erbanlagen eines Individuums wird als Genom bezeichnet, ein Gen ist die kleinste Einheit der biologischen Erbinformation. Es handelt sich bei Genen um Abschnitte der DNA, die den Bauplan für Proteine (Eiweiße) beinhaltet. Je nach Aufgabe des zu erzeugenden Proteins kann die Anzahl der Basenpaare eines Gens unterschiedlich sein und umfasst meist mehrere tausend Basenpaare. Ein Gen kann für mehrere Proteine codieren. Neben dem DNA-Bereich, der für mRNA (und somit für ein funktionsfähiges Protein) codiert, werden auch DNA-Elemente zur Regulation der Genaktivität zu den Bestandteilen eines Gens gerechnet.
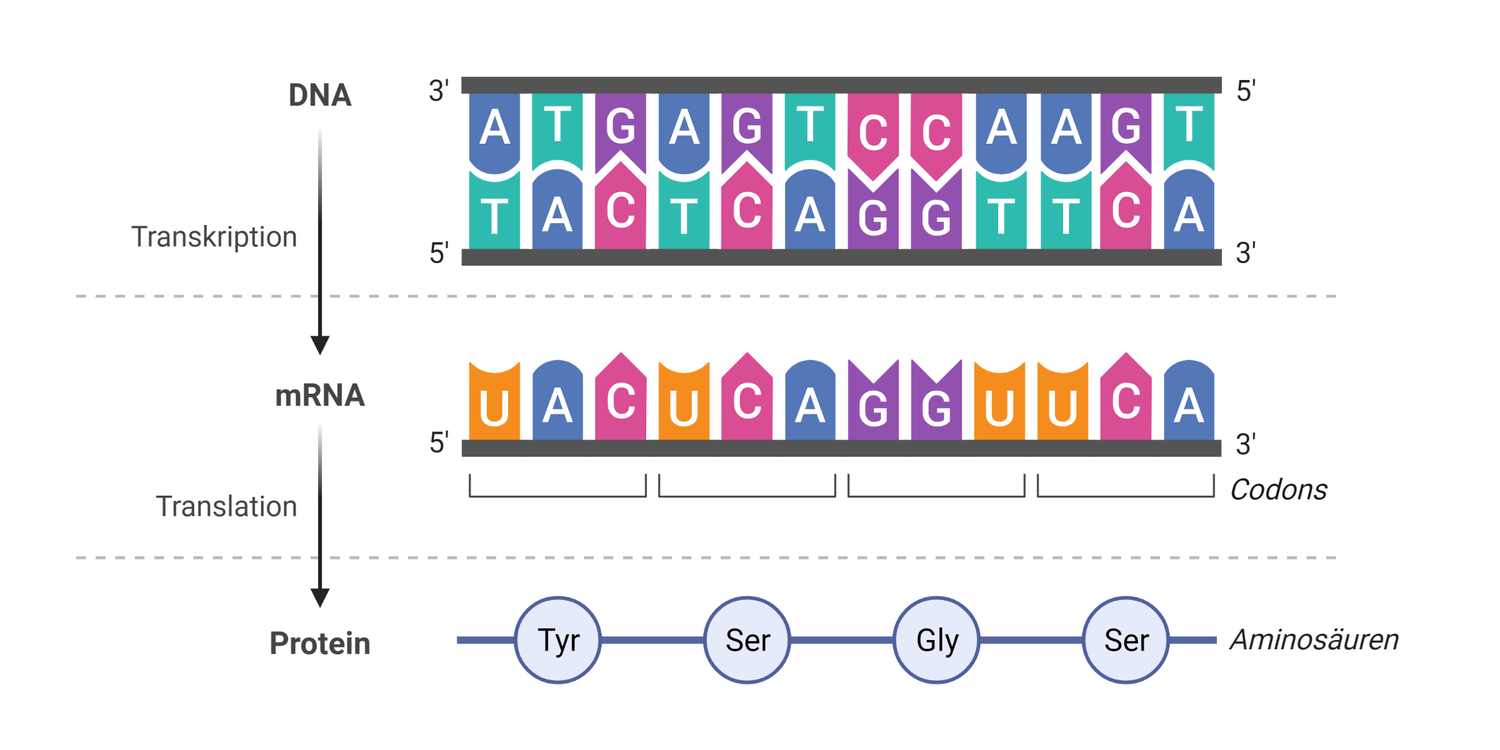
Die Neubildung von Proteinen in einer Zelle bezeichnet man als Proteinbiosynthese. Proteine bestehen aus einer kettenförmigen Aneinanderreihung von Aminosäuren, deren Zahl und Reihenfolge die räumliche Struktur und Funktion eines Proteins festlegen. Die Information der Gene für die Proteinbiosynthese ist in der DNA in einem Triplettcode verschlüsselt. Die DNA wird zunächst in mRNA übersetzt (Transkription), die dann als Vorlage für das Aneinanderreihen der Aminosäuren zum Protein dient (Translation). Je drei Nukleotide bilden eine Informationseinheit (Basentriplett = Codon) für eine Aminosäure. Zusätzlich gibt es noch Codons für den Beginn (Start) und das Ende (Stopp) eines Gens. Die Zuordnung der Tripletts zu spezifischen Aminosäuren bezeichnet man als genetischen Code.
Die Codesonne
Die sogenannte Codesonne ist ein Hilfsmittel zum "Entschlüsseln" des genetischen Codes. Sie zeigt an, welche Basensequenz für welche Aminosäure codiert.
Gelesen wird die Codesonne von innen nach außen: Im Zentrum der Sonne startet man mit dem ersten Buchstaben des genetischen Codes, also A, C, G, oder U - Uracil, da es sich hier um die RNA-Sequenz handelt. Man liest dann nach außen den zweiten Buchstaben im zweiten Kreis und den dritten Buchstaben des Tripletts im dritten Kreis ab. So gelangt man zur Bezeichnung der entsprechenden Aminosäure ganz außen. Es sind die Abkürzungen für die jeweiligen Aminosäuren angegeben sowie die einzelnen Buchstabe, welche diese symbolisieren.
AUG ist das START-Codon für die Translation, bei UAA, UAG sowie UGA handelt es sich um STOP-Codons, an denen die Translation stoppt.
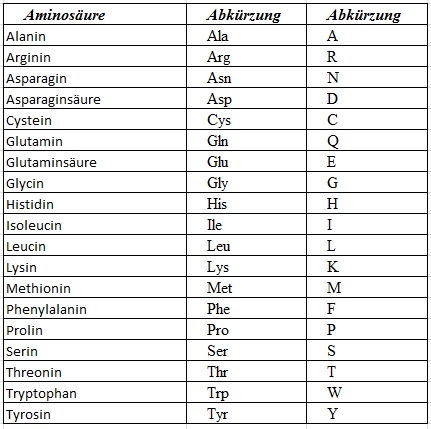
Abkürzungen der Aminosäuren
In der Codesonne werden Abkürzungen für die Aminosäuren verwendet. Hier ihre vollständigen Namen:
DNA- oder mRNA-Sequenz?
Um eine Sequenz mit Hilfe der Codesonne zu entschlüsseln, muss man zunächst wissen: Handelt es sich dabei um eine DNA- oder um eine mRNA-Sequenz?
Liegt ein mRNA-Strang vor, kann man direkt mit der Codesonne starten, da diese auf der mRNA-Sequenz beruht.
Soll allerdings eine DNA-Sequenz analysiert werden, muss bekannt sein, ob es sich dabei um den codogenen oder nicht-codogenen (der mRNA entsprechenden) Strang handelt. Folgende Möglichkeiten gibt es:
- Liegt der codogene DNA-Strang vor, muss dessen Sequenz erst einmal in die komplementäre - der mRNA entsprechende - Sequenz umgewandelt werden. Komplementär bedeutet konkret: A wird zu U (Achtung: U statt T in der RNA!), T wird zu A, C wird zu G, G wird zu C.
- Liegt der nicht-codogene DNA-Strang vor, kann dieser direkt für die Gensonne herangezogen werden. Jedes T muss allerdings in ein U umgewandelt werden.
Universalität des genetischen Codes
Der genetische Code wird von allen Lebewesen gleich verstanden und in Protein umgesetzt. Das heißt: Alle Lebewesen benützen für ihre Erbinformation die gleiche Sprache. Man spricht von der allgemeinen Gültigkeit oder Universalität des genetischen Codes. Ein bestimmtes Gen kann daher theoretisch in allen Lebewesen dasselbe Protein erzeugen, sei es nun in einer Pflanze, in einem Wurm oder in einem Bakterium. Daher funktionieren Gene von Fliegen oder Pflanzen in Säugetierzellen und menschliche Gene in Bakterien. Dies ist die Grundlage für die Gentechnik.
Mit vier verschiedenen Basen und dem Triplett-Code aus drei Basen ergeben sich 64 verschiedene mögliche Kombinationen für Aminosäuren. Tatsächlich aber ist der genetische Code degeneriert: mehrere Basentripletts codieren für ein und dieselbe Aminosäure, und alle natürlich vorkommenden Organismen verwenden nur 20 verschiedene Aminosäuren.